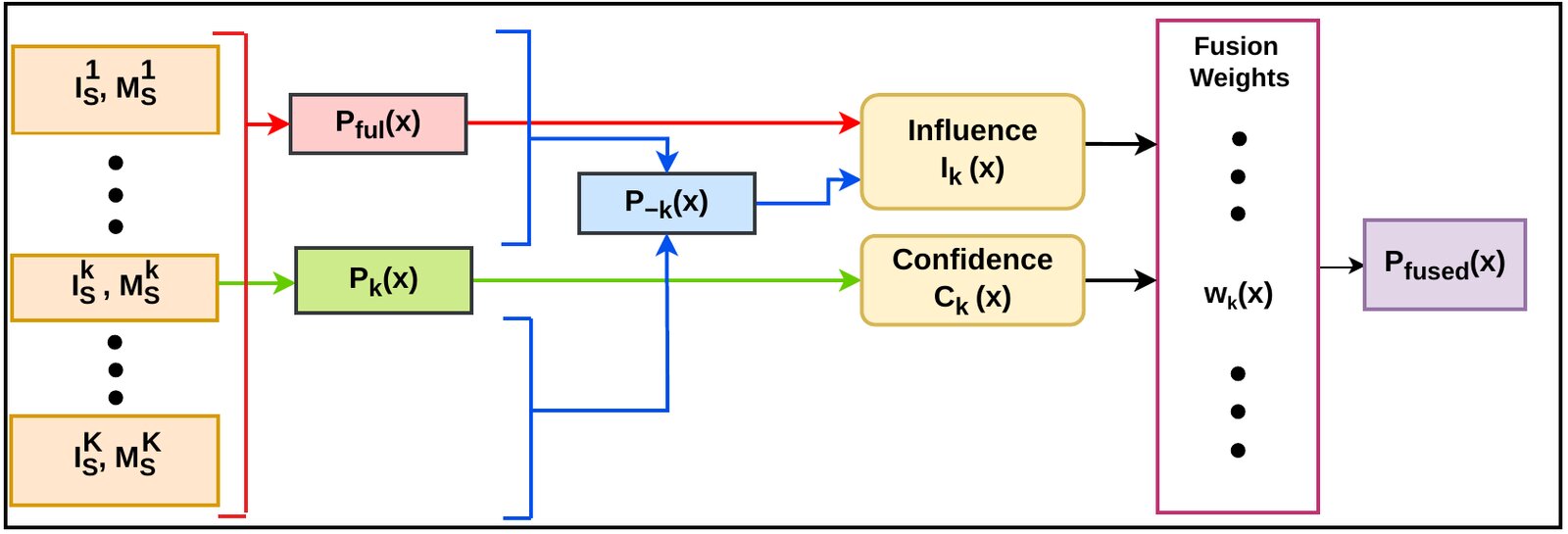
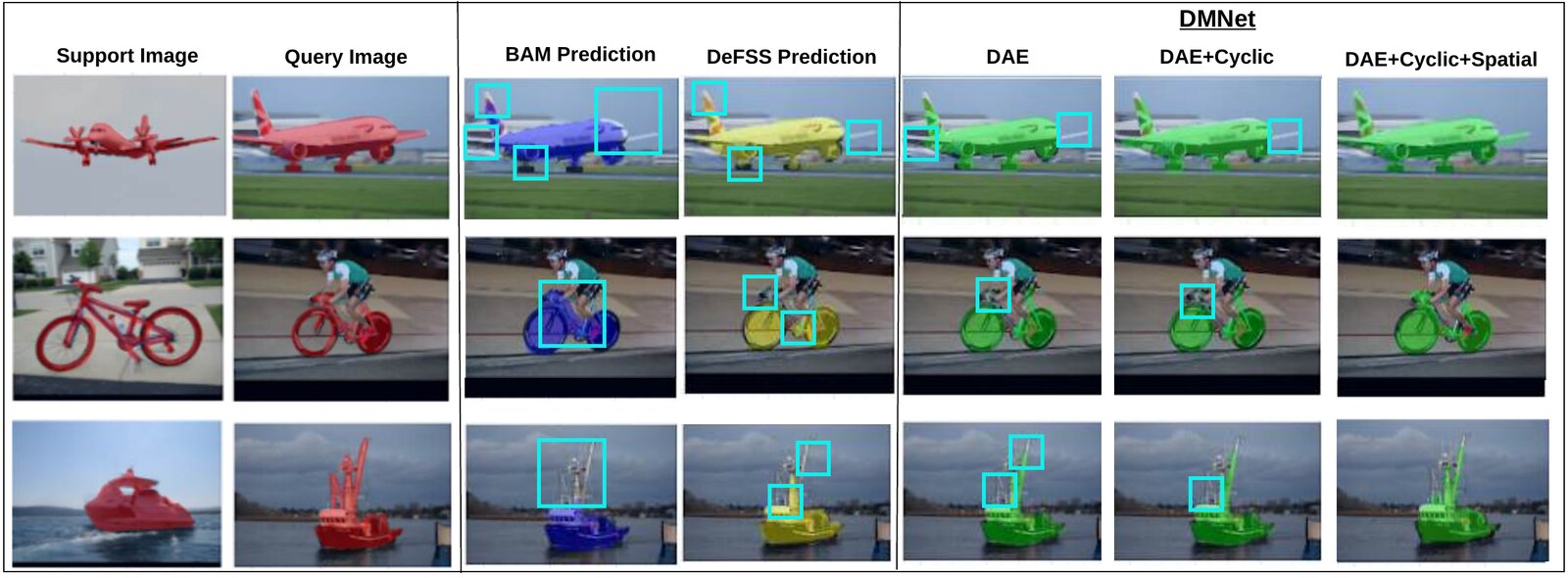
DMNet: Decoupled Matching Network
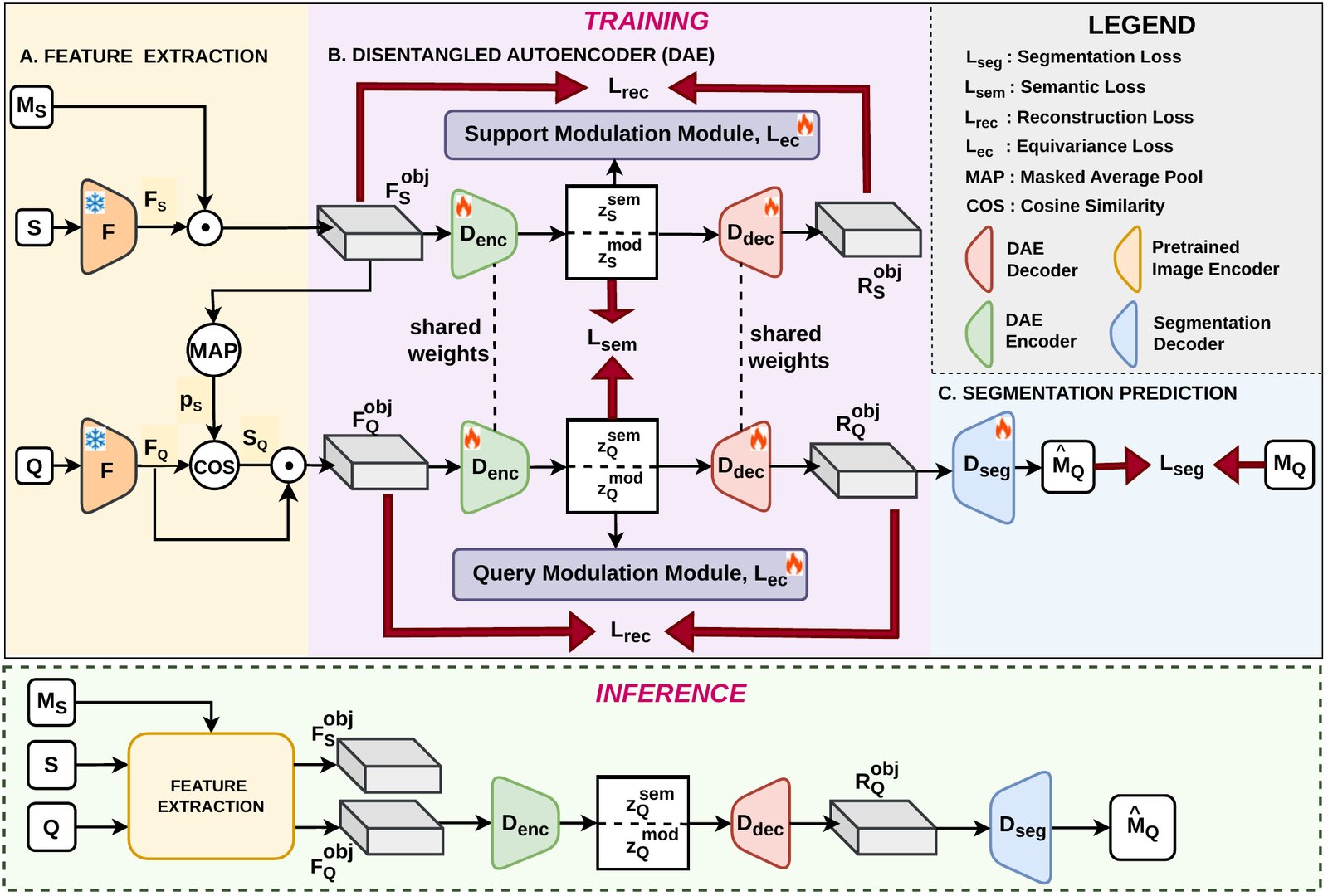
Rather than estimating an explicit geometric transform to align support and query - brittle when object categories and instances are unseen at test time - DMNet takes the opposite approach: geometric variation should never be allowed to disrupt semantic matching in the first place.
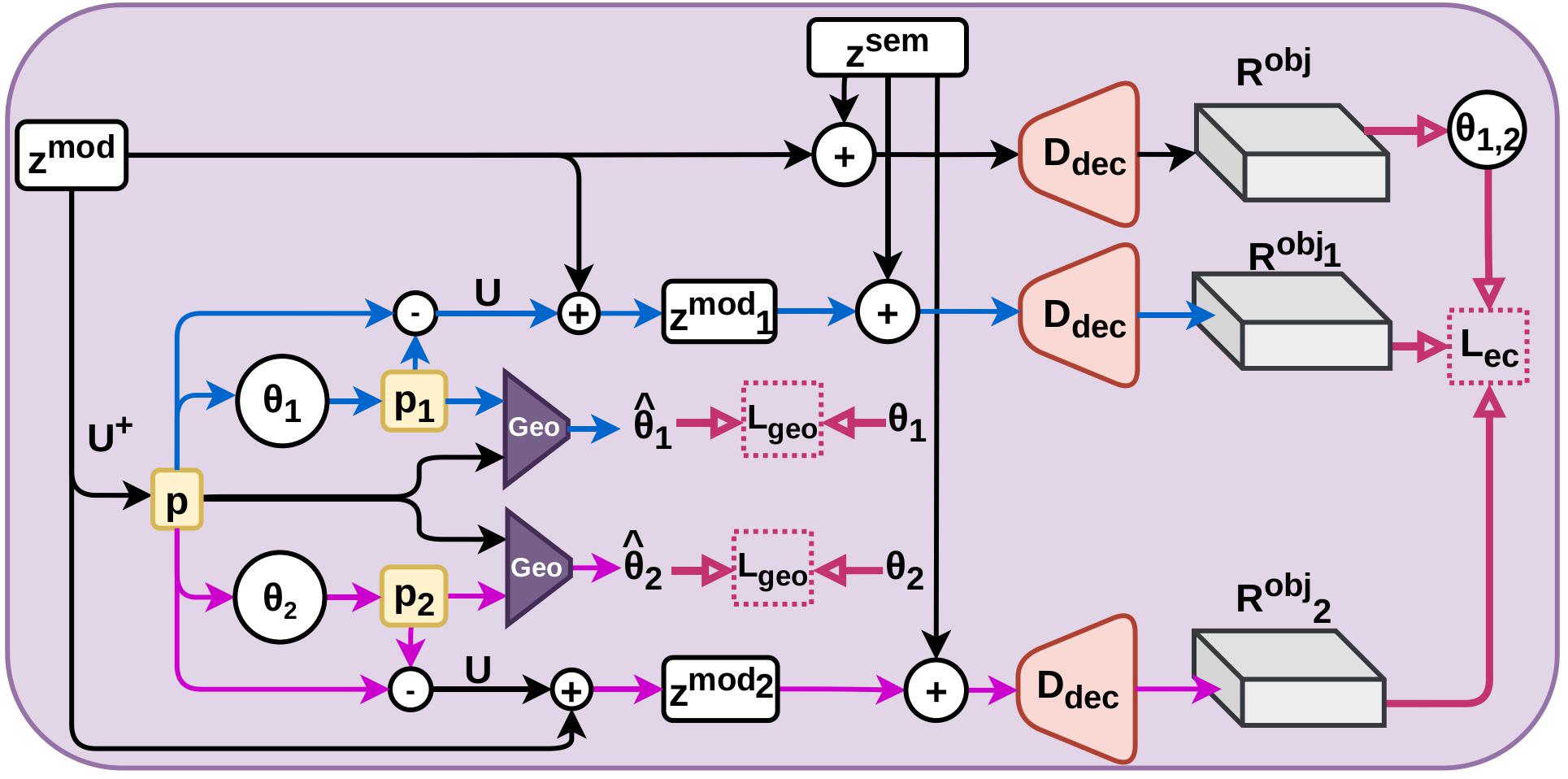
The object-centric features of support and query are passed through a shared encoder and decomposed into two compact latent codes: a semantic code capturing geometry-invariant class identity, and a modulation code - visualized as a 2D geometric pointer - encoding instance-specific pose and scale. A decoder recombines both codes into reconstructed features under an equivariance constraint, so similarity transforms applied in the modulation subspace produce matching transforms in the reconstruction. A lightweight segmentation head Dseg then predicts the query mask from the geometry-decoupled features.